Reproducible builds folks: Reproducible Builds: week 81 in Stretch cycle
What happened in the Reproducible
Builds effort between Sunday
November 6 and Saturday November 12 2016:
Media coverage
Matthew Garrett blogged about Tor, TPMs and service integrity
attestation and how reproducible
builds are the base for systems integrity.
The Linux Foundation
announced
renewed funding for us as part of the Core Infrastructure Initiative. Thank
you!
Outreachy updates
Maria Glukhova has been
accepted into the
Outreachy winter internship and will work with us the Debian reproducible
builds team.
To quote her words
siamezzze: I've been accepted to #outreachy winter internship - going to work with Debian reproducible builds team. So excited about that! <3 DebianToolchain development and fixes dpkg:
- Thanks to a series of dpkg uploads by Guillem Jover, all our toolchain changes are now finally available in sid!
- This means your packages should now be reproducible without having to use our custom APT repository.
- Ximin Luo opened #843925 to remind the fact that dpkg-buildpackage should sign buildinfo files.
- We hope to have detailed post about the new dpkg and the new .buildinfo files for debian-devel-announce soon!
- srebuild / debrebuild work was resumed by Johannes Schauer and others in #774415.
- #844102 filed against lava-dispatcher
- #844103 filed against lava-server
- #844111 filed against python-defaults
- #843698 filed against tunnelx
- #843967 filed against asyncpg
- #843865 filed against keystone
- #844101 filed against suil
- #844232 filed against daisy-player
- #844236 filed against libhtml-lint-perl
- #844228 filed against ebook-speaker
- #843432 filed against libwww-curl-perl
- Added: random_order_in_dh_pythonX_substvars, valac_permutes_get_type_calls
- Updated: timestamps_in_static_libraries
- Chris Lamb (29)
- Niko Tyni (1)
62~bpo8+1 was
uploaded
to jessie-backports by Mattia Rizzolo.
Meanwhile in git, Ximin Luo greatly improved speed by fixing a O(n2)
lookup
which was causing diffs of large packages such as GCC and glibc to take many
more hours than was necessary. When this commit is released, we should
hopefully see full diffs for such
packages
again. Currently we have 197 source packages which - when built - diffoscope
fails to analyse.
buildinfo.debian.net development
- Submissions with duplicate Installed-Build-Depends entries are rejected now that a bug in dpkg causing them has been fixed. Thanks to Guillem Jover.
- Add a new page for every (source, version) combination, for example diffoscope 62.
- DigitalOcean have generously offered to sponsor the hardware buildinfo.debian.net is running on.
- For privacy reasons, the new
dpkg-genbuildinfoincludesBuild-Pathonly if it is under/build. HW42 updated our jobs so this is the case for our builds too, so you can see the build path in the .buildinfo files. - HW42 also updated our jobs to vary the basename of the source extraction
directory. This detects packages that incorrectly assume a
$pkg-$versiondirectory naming scheme (which is whatdpkg-source -xgives but is not mandated by Debian nor always-true) or that they're being built from a SCM. - The new
dpkg-genbuildinfoalso records a sanitisedEnvironment. This is different in our builds, so HW42, Reiner and Holger updated our jobs to hide these differences from diffoscope output. - Package-set improvements:
- Holger refactored the create_meta_pkg_sets job so that it's easier to add new package sets.
- This job is now also using dose-extra from jessie-backports so that it can deal with versioned provides.
- Added 4 new package sets: debian-edu, debian-edu_build-depends, maint_pkg-grass-devel, maint_debian-accessibility, maint_pkg-openstack.
- Switched to using the new URL for tails manifests to generate the tails package set.
- Renamed maint_lua to maint_debian-lua
- Valerie Young contributed four patches for our long-planned transition from SQLite to PostgreSQL.
- In anticipation of the freeze, already-tested packages from unstable and testing on amd64 are now scheduled with equal priority.
 It all started last June when my son had his Janoi (Yagnopavita) ceremony -- the ritual by which a Brahmana boy becomes "twice-born" and eligible to study the Vedas. As well as a profound religious experience, it is also an important social occasion with a reception for as many friends and family as can attend. (I think our final guest total was ~250.) This meant new outfits for everyone which might be exciting for some people but not me. I still don't know why I couldn't just keep wearing the khes and pitambar from the puja but no, apparently that's a faux pas. So I relented and agreed to wear my "darbari" suit from my wedding. And it didn't fit. I knew I had gained some weight in the intermediate 17 years but the thing was sitcom levels of too small. I ended up having to purchase a new one, a snazzy (and shiny!) maroon number with gold stripes (or were they
It all started last June when my son had his Janoi (Yagnopavita) ceremony -- the ritual by which a Brahmana boy becomes "twice-born" and eligible to study the Vedas. As well as a profound religious experience, it is also an important social occasion with a reception for as many friends and family as can attend. (I think our final guest total was ~250.) This meant new outfits for everyone which might be exciting for some people but not me. I still don't know why I couldn't just keep wearing the khes and pitambar from the puja but no, apparently that's a faux pas. So I relented and agreed to wear my "darbari" suit from my wedding. And it didn't fit. I knew I had gained some weight in the intermediate 17 years but the thing was sitcom levels of too small. I ended up having to purchase a new one, a snazzy (and shiny!) maroon number with gold stripes (or were they  Once I got
Once I got 

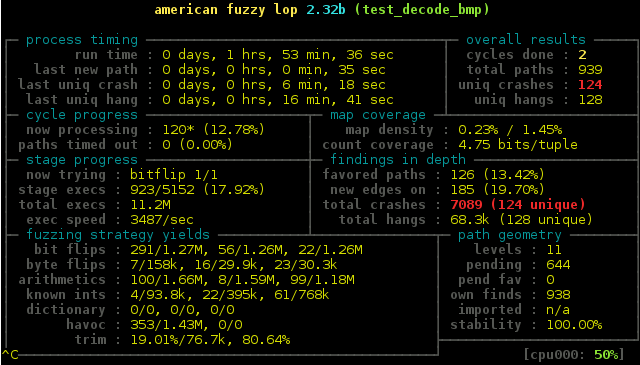
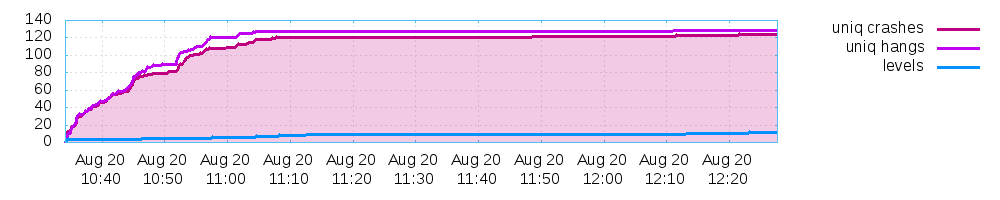

 not much to report but I got at least some RC bugs fixed in the last
weeks. again mostly perl stuff:
not much to report but I got at least some RC bugs fixed in the last
weeks. again mostly perl stuff:
 Here is my monthly update covering a large part of what I have been doing in the free software world (
Here is my monthly update covering a large part of what I have been doing in the free software world ( In 2016-06-18:
In 2016-06-18:
 Numbers
The
Numbers
The 
 Yesterday we have released
Yesterday we have released 
 Writing programs is fun, but making them fast can be a pain. Python programs
are no exception to that, but the basic profiling toolchain is actually not
that complicated to use. Here, I would like to show you how you can quickly
profile and analyze your Python code to find what part of the code you should
optimize.
What's profiling?
Profiling a Python program is doing a dynamic analysis that measures the
execution time of the program and everything that compose it. That means
measuring the time spent in each of its functions. This will give you data
about where your program is spending time, and what area might be worth
optimizing.
It's a very interesting exercise. Many people focus on local optimizations,
such as determining e.g. which of the Python functions
Writing programs is fun, but making them fast can be a pain. Python programs
are no exception to that, but the basic profiling toolchain is actually not
that complicated to use. Here, I would like to show you how you can quickly
profile and analyze your Python code to find what part of the code you should
optimize.
What's profiling?
Profiling a Python program is doing a dynamic analysis that measures the
execution time of the program and everything that compose it. That means
measuring the time spent in each of its functions. This will give you data
about where your program is spending time, and what area might be worth
optimizing.
It's a very interesting exercise. Many people focus on local optimizations,
such as determining e.g. which of the Python functions 





 The
The 

 My monthly report covers a large part of what I have been doing in the free software world. I write it for
My monthly report covers a large part of what I have been doing in the free software world. I write it for 
 What happened in the
What happened in the  This was my fifth month working on Debian LTS. I was assigned 16
hours
by
This was my fifth month working on Debian LTS. I was assigned 16
hours
by  As a follow-up to my post
about
As a follow-up to my post
about